はじめに
近年、個人情報保護法やGDPRなどの個人情報保護法制に加え、EU AI法をはじめとするAI規制も含め、データ関連規制は高度化・複雑化している。特に、2026年8月にはEU AI法のハイリスクAIシステムに対する義務が本格適用される予定であり、データリネージ(データがどこから来て、どのように加工・移動されたかの履歴)の追跡やリスク分類の文書化が求められるなど、AIとデータ保護の規制が重層的に交差する時代に入っている。米国においても連邦レベルでのAI監督の統合が進み、各州でも包括的なAIガバナンス枠組みの整備が加速している。グローバルに事業を展開する企業にとっては、各国で共通化が進む部分と国・地域ごとに異なる部分の双方に同時対応することが不可避となっている。企業においては、単に法令条文を把握し、違反を回避するような受動的な対応だけでは不十分であり、「自社がどのようなデータを、どこで、どの目的で、どのように取り扱っているのか」を常に説明できる体制の構築が求められている。その中核となるのがデータマッピング、すなわち自社のデータ処理活動を体系的に洗い出し、一覧として可視化する取り組みである。
もっとも、データマッピングは「作れば終わり」の一覧表ではない。目的やスコープ(対象範囲)を曖昧にしたまま導入を進めると、データマッピングによってデータ処理活動を管理する意義が共有されず、その結果運用が形骸化し、更新されない資料となり、リスク管理が停滞する恐れがある。近年、各国の規制当局は、書面上の整備だけでは不十分とみなし、プライバシーポリシーやDPIA(データ保護影響評価:個人データの処理がもたらすリスクを事前に評価する手続き)、契約条項などが継続的に見直されている「生きたガバナンス」の証拠を求める傾向を強めている。本連載では、リスク管理部署の視点から、データマッピングを単なるコンプライアンス対応にとどめず、データガバナンスの基盤として実装・運用していくための実践的なアプローチを解説する。
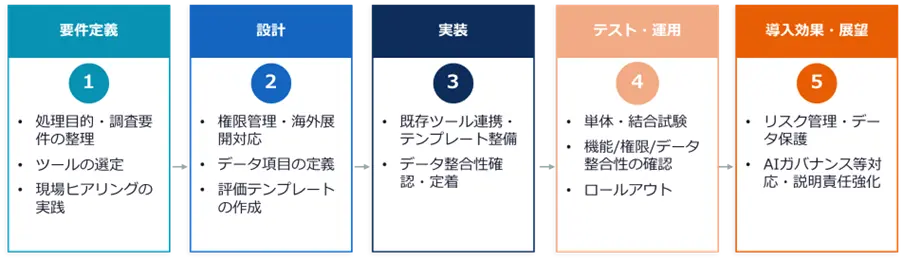
第1回の本稿では、その出発点となる要件定義に焦点を当て、目的整理、スコープ設計、SaaS(クラウド型サービス)と内製の比較、そしてヒアリング方法について解説する。
目的整理 ― なぜデータマッピングを行うのか
要件定義において最初に整理すべきなのは、「なぜデータマッピングに取り組むのか」、すなわち実施目的の明確化である。それを曖昧にしたままデータマッピングを開始すると、「何を作ればよいのか」「どこまでやれば十分なのか」が判断できなくなる。
全社的なデータ処理の観点から整理すると、データマッピングの目的は大きく以下に分類できる。
第一に、法令・規制対応の基盤整備である。個人情報保護法、GDPR、各国のデータ保護法制や、AI関連法制等では、データ処理の適法性、データ保護原則の充足を証明するために、データ処理の内容や目的、第三者提供、越境移転の有無などを正確に説明する責任が求められている。データマッピングは、これらの説明責任を果たすための事実基盤となる。
第二に、リスクコントロールのためのリスク可視化である。どの部署が、どのシステムで、どのようなデータを扱っているかを可視化することで、本来の目的に比べて不要・過剰なデータ収集や保存、アクセス権限の不備といった安全管理措置の不足等のデータ処理におけるリスクを把握できる。
第三に、データ経営実現への備えである。AI活用やデータ利活用を検討する際、既存のデータ処理実態が把握できていなければ、データ経営実現の糸口を掴むことは困難となる。データマッピングは「守り」のためだけでなく、「攻め」の施策を支える基盤でもある。
第四に、AIガバナンスへの対応である。EU AI法をはじめとする各国のAI規制では、AIシステムに用いるデータの品質管理、データリネージの記録、バイアス検証(AIの判断に偏りがないかを確認する作業)のための文書化が求められている。しかし、現時点でデータガバナンスとAIガバナンスの双方において高い成熟度を持つ企業はごく少数にとどまる。多くの企業では、IT部門の承認を得ないまま、従業員が個人のAIチャットボットを業務に使用する、いわゆる「シャドーAI」の問題が広がっている。データマッピングは、こうしたAI利用の実態を把握し、適切に管理するための出発点ともなる。
このように、データマッピングの目的は一つに限られない。重要なのは、法令対応、リスク可視化、データ経営、AIガバナンスといった複数の目的のうち、どの目的を優先するのか、どれだけ具体的にデータマッピングを実装するのかを明示することである。目的と実装目標が定まれば、後続のスコープ設計や機能要件の解像度を高めることができる。
スコープ設計 ― データ管理の優先順位の判断基準
次に重要となるのがスコープ設計である。ここでいうスコープとは、データマッピングの対象とする業務範囲を指す。
データマッピングに取り組む際、「全社のすべてのデータ処理を一度に把握しよう」と考えがちだが、これは現実的ではない。初期段階でスコープを広げすぎると、各部署へのヒアリング負荷が一気に高まり、結果として情報の粒度が揃わないまま記録だけが増えていく。その結果、実際の運用では参照されなくなるケースも少なくない。
スコープ設計では、一例として以下の観点が重要となる。
- 対象とするデータの種類(個人データのみか、業務データも含めるか)
- 対象とする組織範囲(本社のみか、海外子会社を含むか)
- 対象とするシステム(主要システムのみか、部門独自ツールも含むか)
- 対象とするデータのライフサイクル(取得・利用・保存・削除まで含むか)
- 対象とするAIシステム(社内で利用されるAIツール、シャドーAIを含むか)
データマッピングを主管するリスク管理部署としては、まず、データ処理リスクの高い領域から着手することが現実的である。例えば、顧客情報を大量に扱う部門(顧客情報の漏洩リスク)、外部委託や海外移転が発生している業務(委託先での営業情報の漏洩リスク)、過去に安全管理措置の不備によってインシデントが発生した領域・部署などである。
また、スコープは固定的なものではなく、段階的に拡張する前提で設計すべきである。初期フェーズでは、「主要なデータ処理の存在、目的、リスクがあるかどうか」を説明できる状態を一つの目安とする。そして、運用が安定した後に対象範囲を広げていく。
なお、EU AI法の施行に伴い、AIシステムのインベントリ(台帳)作成やデータリネージの文書化が求められるため、スコープ設計においてはAIシステムが処理するデータも早期に視野に入れておくことが望ましい。さらに、EUでは2025年末に提案された「Digital Omnibus」(AI法・GDPR・NIS2(ネットワーク・情報セキュリティ指令)等の複数のデジタル規制を一体的に整理・簡素化する法案パッケージ)に見られるように、規制間の統合が進んでいる。そのため、一つの規制だけでなく、複数の規制に横断的に対応できるスコープの柔軟性も考慮すべきである。
このように、段階的アプローチを前提に要件定義を行うことが、長期的なデータマッピング運用の実現につながる。
SaaSか内製か ― 何を基準に選ぶか
要件定義において避けて通れないのが、データマッピングをSaaS型ツールで実現するか、内製ツールとして構築するかの判断である。
SaaS型ツールの主な特徴としては、以下が挙げられる。
- データ処理を整理するためのテンプレートや標準項目がベンダー側で用意されている
- 法改正への追随がベンダー側で行われることが多い
一方で、以下のような制約も存在する。
- 自社業務に完全に合致しない場合がある
- 権限管理や構造設計の柔軟性にSaaS独自の制約がある
- サービス料金の改定など、将来的なコスト変動が予測しにくい
内製の場合は、柔軟性が高く、自社の業務に最適化した設計が可能であるという利点がある。一方で、設計・開発リソースの確保が必要となり、開発・運用が属人化した場合、ノウハウが継承されないリスクも生じる。
どちらを選択するかの判断基準は、「どちらが優れているか」ではなく、自社の目的やスコープに無理なく適合するかどうかである。例えば、以下のような判断基準が考えられる。
- 自社で UI/UX を細かくカスタマイズしたいか
- 法改正対応の迅速性を求めるか
- 内製エンジニアやDX組織の成熟度
- 長期的なTCO(Total Cost of Ownership:ソフトウェアの導入費用だけでなく、運用保守や将来のアップグレードを含む総保有コスト)をどう考えるか
- AIガバナンス機能(AIシステムのインベントリ管理、データリネージ追跡、リスク分類等)への対応状況
そのため、まずは典型的なデータ処理業務を対象に、限定的な範囲で手動のデータマッピングを実施し、その結果を踏まえて SaaS と内製それぞれのメリット・デメリットを比較して判断するというアプローチが現実的である。重要なのは、この判断を要件定義フェーズで行い、後戻りを防ぐことである。
なお、近年のSaaS型ツールでは、「アクティブメタデータ」(データそのものではなく、データの所在や種類、更新履歴といった「データに関するデータ」をリアルタイムに管理する仕組み)を活用した先進的な機能が進化している。具体的には、社内にどのようなデータ資産があるかを自動的に検出し、データがどこから来てどのように加工・移転されたかの履歴を自動で可視化し、さらにポリシーの適用までをリアルタイムで自動化できる機能を備えた製品が増えている。一方で、このようなメタデータ管理を高い水準で実践できている企業はまだ少数にとどまるため、自社の現在の成熟度と将来的な自動化への移行可能性を考慮した選定が求められる。
ヒアリング方法 ― 情報を集める

要件定義を進めるうえで重要な要素の一つが、ヒアリング方法である。データマッピングの成否は、データ処理を行う現場から、いかに正確な実態を引き出せるかに大きく左右される。
よくある失敗例として、調査漏れを過度に懸念するあまり、必要以上に詳細な質問票を作成・配布してしまうケースが挙げられる。一見すると網羅的な調査ができるように見えるが、実際には現場担当者の負担が大きく、回答の粒度がばらつきやすい。その結果、実際のデータ処理の状況を正確に反映しない情報が集まってしまうことが多い。
データマッピングにおけるヒアリングでは主に以下の点を意識すべきである。
- 「何のために聞いているのか」を最初に説明する
- 法令用語ではなく業務用語で質問する
- 正解を求めるのではなく実態を聞き出す
- 不明点はその場で深掘りする
例えば、「個人データを処理する業務の目的は何ですか」と聞くのではなく、「この業務で顧客の名前や連絡先はどのような目的で使っていますか」といった具体的な聞き方が有効である。
また、ヒアリング結果をそのまま記録するのではなく、要件定義の観点で整理・補正することも重要である。加えて、ヒアリングによる手動の情報収集には限界がある。将来的には、メタデータ管理ツール(データの所在や種類、更新履歴などを一元管理するツール)やデータカタログ(社内に存在するデータ資産の目録を自動的に作成・維持する仕組み)との連携により、データ処理実態を自動的に把握することを視野に入れることが望ましい。例えば、既存システムのログやアクセス権限情報を活用し、ヒアリングで得られた情報を補完・検証することで、データマッピングの精度と持続性を高めることができる。
要件定義の設計・サブタスク項目整理
ここまで、目的整理、スコープ設計、実現方式の検討、ヒアリング方法について述べてきた。
これらの検討を踏まえ、設計に進むための判断事項を体系的に整理しておく必要がある。
要件定義では、少なくとも次の観点について明確にしておくことが求められる。
| No | 項目 | 目標 |
|---|---|---|
| 1 | 目的・スコープ | データマッピングの対象とする領域を定める |
| 2 | 想定ユースケース(業務シナリオ) | データマッピング活動の具体的なイメージを作る |
| 3 | ステークホルダー・体制 | 人や組織をどこまで巻き込むか整理する |
| 4 | データモデル要件 | 何を記録するか定める |
| 5 | 入力方式・UX要件 | 管理データの形式を整える |
| 6 | ワークフロー要件(統制) | 組織的な管理の流れを定める |
| 7 | 検索・可視化・レポート要件 | データマッピングの見える化の形を定める |
| 8 | 連携要件(他システムとのつながり) | 既存システムとの接続方法やデータ流通の前提を整理する |
| 9 | セキュリティ・プライバシー要件 | 管理情報そのものの保護水準と統制方針を定める |
| 10 | コンプライアンス要件 | 満たすべき法令・規制・社内基準との整合性を明確にする |
| 11 | 非機能要件 | 性能・可用性・拡張性など運用基盤の前提条件を定める |
| 12 | リスク管理要件 | データ処理リスク管理の基準や評価の方法等を定める |
| 13 | データ移行・初期投入計画(要件として決める) | 既存資料をどの水準で整理・移行するかを決める |
| 14 | 運用ルール(導入後に揉めやすい所) | 更新頻度・責任分担・例外処理の方針を明確にする |
| 15 | 調達・契約・費用の前提(要件定義で固める) | 導入形態や契約条件の前提を整理する |
| 16 | AIガバナンス要件 | AIシステムのインベントリ管理・データリネージ・リスク分類の基準を定める |
実際の要件定義では、上記の各項目について、その詳細をサブタスク化する必要がある。
データマッピングに必要な要件定義項目とそのサブタスクの例を別紙にまとめた。
サブタスクの詳細度は、プロジェクトの期間・工数・費用に直結するため、データガバナンスに投入可能な予算やリソースとのバランスを考慮して決定する必要がある。また、要件定義で定めるサブタスク項目は、そのまま運用開始後の管理項目となるため、運用上の実行可能性を考慮して設定することが望ましい。管理対象の質・量が不十分な状態は避けるべきであるが、スコープを広げすぎるとワークロードが増大し、「運用疲れ」やコスト超過を招きかねないことから、実効性と負担のバランスを見極めることが肝要である。
次章において、要件定義項目のいくつかを取り上げ、細部サブタスクの検討例を紹介する。
要件定義サブタスクの検討例
目的・スコープ
| 項目 | 内容 |
|---|---|
| 導入目的 | RoPA作成、DPIA効率化、リスク可視化、監査対応、横断検索 |
| 対象範囲 | 法人/子会社/国、部門、システム群、プロセス、データカテゴリ |
| 対象データ | 個人データ、機微情報、非個人データ、ログ、識別子など |
| 完了の定義 | 成果物・KPI・導入成功の判断基準 |
目的・スコープはデータマッピング導入の起点であり、後続のデータモデル、ワークフロー、統制、レポーティング、連携要件など全体設計の深度を決める基本方針となる。導入目的には、法令遵守の実効性向上に加え、RoPA(Record of Processing Activities:GDPRが求めるデータ処理活動の記録)の作成やDPIAの効率化、リスクの可視化、監査対応の迅速化、横断検索によるコミュニケーション強化といった業務価値が含まれる。これらの目的は相互に関連するため、優先度と達成水準を初期段階で明確にしなければ、粒度や統制のレベルが部署ごとにばらつき、更新停止や形骸化につながりやすい。
対象範囲は、法人・子会社・国、部門、システム群、業務プロセス、データカテゴリといった複数階層で定義する。全社一括導入は統一的なデータマッピングの実現に寄与するが、同時に実施負荷が大きいため、顧客データ大量処理、外部委託や越境移転、過去インシデントのあった領域など、リスクの高い範囲から段階的に展開する方が現実的である。
システム起点の導入も可能だが、業務理解が不十分だと処理主体の誤りやデータフローの抜け漏れが発生しやすいため、対象部門・処理業務の基準、調査粒度を明確にし、ヒアリング計画や承認フローと連動させることが重要となる。
対象データは、個人データ、機微情報、非個人データ、ログ、識別子などデータ分類に応じて管理粒度やモデル要件が変わる。機微情報を含む場合は統制・リスク評価の強度が増し、ログを含める場合は自動連携や差分取込の設計が現実的となる。初期段階から全範囲を対象にする必要はなく、優先ユースケースで必要な最小セットから開始し、運用の安定後に徐々に拡張する方法が合理的である。
完了の定義では、成果物(記録台帳、可視化ビュー、RoPA・監査向けレポート、承認・変更管理フロー、連携仕様)とKPI(Key Performance Indicator:成果を測定するための主要指標。ここでは登録率、欠落率、承認リードタイム、棚卸完了率、監査指摘削減、RoPA自動化率などが挙げられる)を明確にし、責任分担(RACI:誰が実行し、誰が説明責任を負い、誰に相談し、誰に報告するかを整理する枠組み)や検証方法を含めて合意することで、導入後の運用定着と改善サイクルが確保される。
想定ユースケース(業務シナリオ)
| 項目 | 内容 |
|---|---|
| 主要ユースケース | 登録、更新、棚卸、承認、変更管理、監査提出、レポート出力 |
| 実施頻度 | 年次棚卸、随時変更、プロジェクト起点での増加 |
| 例外ケース | 緊急対応、暫定登録、後追い補完、第三者照会 |
要件定義において「想定ユースケース(業務シナリオ)」を明確化することは、データマッピングを現実の業務運用に適合させるうえで不可欠である。目的やスコープを整理しただけでは、どの業務シーンでデータが登録・更新され、どの部署がどの頻度で利用するのかといった具体的な運用イメージが共有されず、設計段階で想定漏れが生じやすい。ユースケースはこのギャップを埋め、データモデル、ワークフロー、UX 要件の精度を高める基盤となる。
代表的なユースケースは「登録」「更新」「棚卸」「承認」「変更管理」「監査提出」「レポート出力」などデータライフサイクル全般である。特に登録・更新・承認は現場と管理側の双方が関与するため負荷が大きく、事前にユースケースとして整理することで、入力補助機能、承認フローの複雑度、権限設定などを適切に設計できる。
また、年次棚卸のような定期業務と、随時の変更や新規プロジェクト開始時に発生する非定期業務が混在しているため、各プロセスの発生頻度を可視化しておくことが重要である。これにより、システム負荷や運用体制、通知・リマインド機能の要否など、非機能・運用要件の検討が容易になる。頻度が高い業務については、入力の簡易化やテンプレート化、過去データ流用など UX の工夫も必要となる。
さらに、緊急対応、暫定登録、後追い補完、第三者照会などの例外ケースも事前に定義すべきである。例外には柔軟な取り扱いが求められる一方、記録や証跡の確保は必須であり、標準フローと例外フローの境界が曖昧だと運用が混乱する。例外ケースをユースケースとして明確化することで、ルールが整理され、内部統制上のリスクを最小化できる。
総じてユースケース定義は、データマッピングを「作って終わり」の台帳にせず、現場で継続的に利用されるガバナンス基盤にするための重要工程である。要件定義の段階で業務シナリオを丁寧に洗い出すことで、設計精度が高まり、運用開始後の手戻りや定着不良を防止できる。
入力方式・UX要件
| 項目 | 内容 |
|---|---|
| 入力UI | フォーム、表形式、ウィザード、一括編集 |
| 一括取込 | Excel/CSVテンプレ、必須列、バリデーション、差分取込 |
| 入力補助 | 入力候補値表示、マスタ参照、過去データの活用、複製入力、テンプレート |
| 表記ゆれ対策 | データ形式、統制語彙、正規化ルール、自由記述の扱い |
| 多言語対応 | 日本語/英語、用語辞書 |
データマッピングの要件定義において「入力方式・UX要件」は、現場が継続的に情報を登録・更新し、最新かつ正確な状態を維持するための中核となる。どれほど精緻なデータモデルを設計しても、入力負荷が高ければ運用は停滞するため、目的・スコープ・ユースケースを踏まえ、現実的に運用可能な仕組みへ落とし込むことが重要である。
まず重要となるのが「入力UI」である。フォーム形式は必須項目の正確な入力に、表形式は大量データの確認や比較に、ウィザード形式は初心者でも迷わず登録できる点にそれぞれ強みがある。誰がどの頻度でどの状況で入力するかというユースケースと密接に関連するため、UIの好みではなく業務とガバナンス両面から検討する必要がある。
次に、「一括取込」機能は初期導入と運用の双方で不可欠である。Excel/CSVテンプレート、必須列の指定、バリデーション、差分取込の仕組みは、多くの企業が既存資料をExcelで管理している現状に適合し、初期移行や大量更新の効率化に直結する。
現場負荷の軽減と入力精度向上のためには、「入力補助」も重要である。候補値の提示、マスタ参照、過去データ流用、複製機能、テンプレート化などにより、繰り返し利用される項目の統一と効率化が実現し、運用の定着に寄与する。
加えて、データ品質確保のため「表記ゆれ対策」をあらかじめ定義する必要がある。データ形式(選択肢、フリーテキスト、数値、日付など)、共通語彙、正規化ルール、自由記述項目の扱いなどを標準化し、入力補助と組み合わせて統制的に管理することで、検索性・分析性・リスク管理の水準を維持できる。
グローバル展開を前提とする場合は、「多言語対応」も重要となる。日本語/英語の切替や用語辞書の提供により、異なる言語下でも同一構造で管理でき、翻訳ゆれを防いでガバナンスの一貫性を確保できる。
総じて入力方式・UX要件は、データマッピングを現場に定着させ、組織横断の統制とリスク管理を実現する基盤であり、全体設計の中心的要素である。
まとめ
データマッピングをガバナンス基盤として定着させるうえで、初期の要件定義は極めて重要である。本稿では、目的の整理、スコープ設計、SaaS と内製の比較検討、そして現場実態を正確に把握するためのヒアリング方法を整理した。これらはいずれも「何をどの深度で管理するか」を定める前提であり、ここが曖昧なままでは設計負荷の増大や運用の形骸化につながる。特に、各国の規制当局が「生きたガバナンス」の実践を重視する傾向を強めている現在、データマッピングは一度作成して終わりではなく、継続的に見直される動的な管理基盤として設計する必要がある。
さらに、要件定義では目的・スコープ、ユースケース、体制、データモデル、入力方式、ワークフロー、可視化、連携、セキュリティ、非機能、リスク管理、データ移行、運用ルール、契約前提、AIガバナンスなど、多岐にわたる項目を整理する必要がある。とりわけ、EU AI法の本格施行を控え、AIシステムのデータリネージやリスク分類を要件定義の段階から組み込むことの重要性が増している。加えて、メタデータ管理の自動化やデータカタログとの連携など、将来的な運用効率化の方向性も視野に入れた設計が求められる。これらを実務レベルに落とし込むためには、各項目をサブタスクとして分解し、粒度と優先度を定義する作業が不可欠であり、サブタスク数や深度は工数や費用、運用負荷に直結するため慎重な設計が求められる。
次回の第2回では、これら要件をもとに進む「設計フェーズ」に焦点を当て、データモデルやワークフロー、統制、可視化など、実装精度を左右する具体的な設計ポイントを解説する。AIガバナンスとの統合設計や、グローバル規制環境の変化に対応するためのデータモデルの柔軟性についても取り上げる予定である。